











گوگل: دقت واقعی چتباتهای هوش مصنوعی از ۷۰ درصد عبور نمیکند
زمان انتشار: 16 دسامبر 2025 ساعت 11:56
دسته بندی: اخبار تکنولوژی
شناسه خبر: 1136444
زمان مطالعه: 7 دقیقه

گوگل: دقت واقعی چتباتهای هوش مصنوعی از ۷۰ درصد عبور نمیکند
این شرکت با انتشار گزارشی صریح درباره میزان قابلاعتماد بودن چتباتهای هوش مصنوعی فعلی، تصویری نهچندان امیدوارکننده ارائه داده است. بر اساس نتایج بهدستآمده از مجموعه معیارهای جدید FACTS، حتی پیشرفتهترین مدلهای هوش مصنوعی نیز برای عبور از آستانه دقت واقعی ۷۰ درصد با دشواری مواجه هستند.
در این میان، Gemini 3 Pro بهعنوان دقیقترین مدل بررسیشده، موفق به ثبت دقت کلی ۶۹ درصدی شده است. سایر مدلهای پیشرو متعلق به شرکتهایی مانند OpenAI، Anthropic و xAI نیز عملکرد ضعیفتری از خود نشان دادهاند. جمعبندی این یافتهها ساده اما نگرانکننده است: این چتباتها، حتی زمانی که پاسخهای خود را با اطمینان ارائه میکنند، بهطور میانگین از هر سه پاسخ، یکی نادرست است.
به گزارش اخبار زنده و به نقل از Digitaltrends، اهمیت این معیار از آنجا ناشی میشود که بسیاری از آزمونهای رایج هوش مصنوعی، بیشتر بر توانایی انجام یک وظیفه تمرکز دارند تا صحت واقعی اطلاعات تولیدشده. این شکاف، بهویژه در حوزههایی مانند امور مالی، مراقبتهای بهداشتی و خدمات حقوقی، میتواند پیامدهای پرهزینهای به همراه داشته باشد. پاسخهایی که روان و قانعکننده به نظر میرسند اما حاوی خطا هستند، در شرایطی که کاربران به درستی اطلاعات اعتماد میکنند، میتوانند خسارتهای جدی ایجاد کنند.
آزمون دقت گوگل چه چیزی را نشان میدهد؟
مجموعه بنچمارک FACTS توسط تیم FACTS گوگل و با همکاری پلتفرم Kaggle طراحی شده است تا دقت واقعی مدلهای هوش مصنوعی را در چهار سناریوی کاربردی دنیای واقعی بهطور مستقیم ارزیابی کند.
در یکی از این آزمونها، «دانش پارامتری» سنجیده میشود؛ یعنی بررسی میشود که آیا مدل میتواند صرفاً بر اساس دانستههای آموختهشده در زمان آموزش، به پرسشهای مبتنی بر واقعیت پاسخ دهد یا خیر.
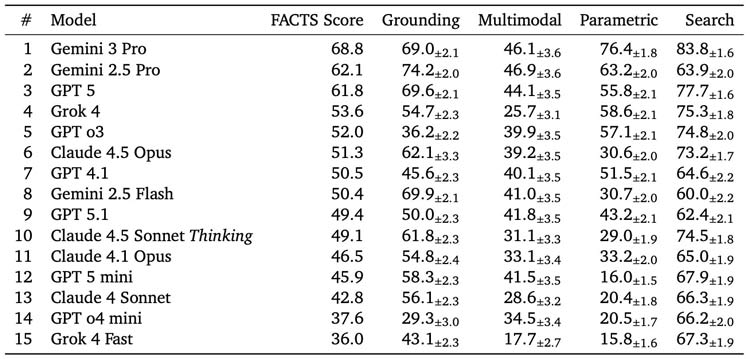
آزمون دوم، عملکرد جستوجو را مورد ارزیابی قرار میدهد و میزان توانایی مدلها در استفاده از ابزارهای وب برای بازیابی اطلاعات دقیق را میسنجد. آزمون سوم بر «پایبندی به منبع» تمرکز دارد؛ به این معنا که آیا مدل بدون افزودن جزئیات نادرست، به سند ارائهشده وفادار میماند یا خیر. آزمون چهارم نیز به درک چندوجهی اختصاص دارد و توانایی مدلها در تفسیر صحیح نمودارها، دیاگرامها و تصاویر را بررسی میکند.
نتایج بهدستآمده، اختلاف قابلتوجهی میان مدلها را نشان میدهد. Gemini 3 Pro با امتیاز ۶۹ درصد در صدر جدول FACTS قرار گرفته و پس از آن، Gemini 2.5 Pro و ChatGPT-5 از OpenAI با حدود ۶۲ درصد جایگاههای بعدی را به خود اختصاص دادهاند.
مدل Claude 4.5 Opus با نزدیک به ۵۱ درصد و Grok 4 با حدود ۵۴ درصد در رتبههای پایینتر قرار دارند. در این میان، وظایف چندوجهی ضعیفترین عملکرد را در کل جدول به ثبت رساندهاند و دقت آنها در بسیاری موارد به کمتر از ۵۰ درصد رسیده است.
این موضوع از آن جهت حائز اهمیت است که چنین وظایفی شامل تفسیر نمودارها، دیاگرامها و تصاویر میشوند؛ حوزههایی که در آنها یک چتبات ممکن است با اطمینان کامل، نمودار فروش را اشتباه بخواند یا عدد نادرستی را از یک سند استخراج کند و در نهایت، خطاهایی ایجاد شود که تشخیص آنها دشوار اما جبرانشان پرهزینه است.
در نهایت، پیام اصلی این گزارش آن نیست که چتباتهای هوش مصنوعی ابزارهایی بیفایده هستند، بلکه تأکید بر این نکته است که اعتماد بیچونوچرا به آنها میتواند خطرناک باشد. دادههای منتشرشده از سوی گوگل نشان میدهد که هرچند هوش مصنوعی در مسیر پیشرفت قرار دارد، اما همچنان پیش از آنکه بتوان آن را بهعنوان منبعی قابلاتکا برای حقیقت در نظر گرفت، به تأیید، نظارت و مداخله انسانی نیازمند است.



